Mysql
[TOC]
Mysql运行原理
bin目录
mysqld:直接启动一个mysql服务器进程
mysql_safe :启动脚本,会间接调用mysqld,并持续监控服务器运行状态,当进程出现问题,可以帮助重启服务器,还可以输出错误日志。
mysql.server:启动脚本,间接调用mysql_safe,可在后面加入start参数来启动服务器。
mysqld_multi:启动脚本,可以启动和停止多个mysql进程
mysql连接
mysql采用tcp作为服务器与客户端的网络通信协议,mysql启动时会默认申请3306端口,等待客户端连接,如需更改,可以在启动时加上-P参数
mysqld -P3307登陆mysql
mysql -h ip -P 3306 -uroot -p([密码)UNIX域套接字
如果服务器和客户端都在类UNIX的同一台机器,可以使用UNIX域套接字进行通信
mysql服务器程序默认监听的UNIX域套接字文件名称是/tmp/mysql.sock
如需更改,在启动服务器时,指定socket参数
mysqld --socket=path如果客服端想通过UNIX域套接字进行通讯,也需要显式指定UNIX域套接字文件名称
mysql -hlocalhost -uroot --socket=path -p 处理请求过程
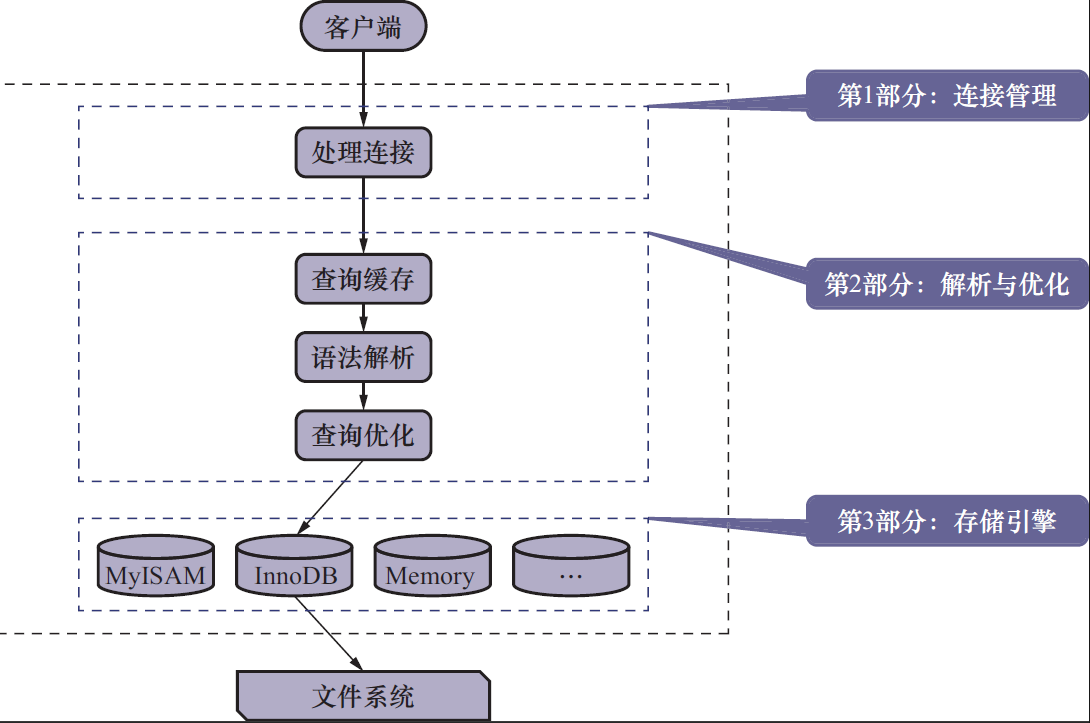
连接管理
每个客户端连接服务器时,服务器会创建一个线程,专门处理与这个客户端的交互。
当客户端退出时,服务器不会立即销毁线程,而是缓存起来,在另一个新的客户端再连接时,把这个线程分配给新的客户端。
从而不会去反复创建和销毁
解析与优化
查询缓存
如果查询请求中出现重复的查询,mysql第一次会把查询结果和请求缓存起来,后续的重复请求会直接查询缓存中的请求和结果。
但如果请求有所不同则不会识别,系统函数,自定义变量,系统表这类请求不会被缓存。
mysql缓存系统会监控每张表,如果表数据或结构被修改,则删除缓存。
语法解析
没有查询到缓存后,mysql会对查询语句分析,判断其是否正确,然后将需要查询的表和条件提取出来,放在mysql内部使用的一些数据结构上。
查询优化
将语句进行优化,方法包括转换连接,表达式简化等。
可以通过EXPLAIN 来查看查询计划。
存储引擎
常用的时InnoDB和MyISAM,InnoDB是mysql的默认引擎(5.5.5版本以后,之前为MyISAM)
设置存储引擎
CREATE TABLE table_name(
) ENGINE = MyISAM ;修改存储引擎
ALTER TABLE table_name ENGINE = MyISAM ;连接白名单
use mysql
select user,host from user看root用户的host是否为localhost
如果为localhost,则只能本地登陆,所以要将localhost改为可以远程的ip
如果是指定的IP,可以用:
grant all privileges on *.* to 'root'@'[允许的ip]' identified by '[密码]' with grant option;
flush privileges; 通过所有IP
grant all privileges on *.* to 'root'@'%' identified by 'root' with grant option;
flush privileges;Mysql 配置与启动
命令行
选项名前加-- , 如果选项名是多个单词,可以用- 或_连接
mysqld --skip-networking --default-strage-engine=MyISAM
#选项名,= , 选项值直接不能有空格skip-networking : 禁止使用TCP/IP 网络通信
default-strage-engine : 设置默认引擎
更多选项执行mysql --help 查看
配置文件
my.cof
配置文件寻找排序
/etc/my.cnf > /etc/mysql/my.cnf> SYSCONFDIR/my.cnf> $MYSQL_HOME/my.cnf
SYSCONFDIR是使用CMake构建Mysql时指定的目录
配置文件格式
[server]
option 1
option 2 = value 2
[mysqld]
[client]
[mysqladmin]
不同的选项组给不同的程序使用,除了[server]和[client] 分别作用与服务器和客户端
mysqld_safe 和 mysql.server 都会读取[mysqld]。
配置文件优先级
mysql会按上面提到过的顺序搜索文件.
但也可以使用--defaults-file指定配置文件,如果我呢见无法正常读取则会报错.
也可以使用--defaults-extra-file指定额外的配置文件``
如果多个配置文件有相同启动项,则以最后一个为准
在同一个配置文件有相同启动项,则以最后一个出现组中的启动项为准
命令行比配置文件优先级高
系统变量
查看系统变量:
show global|session variables like ''
#此处选项名的各个单词之间必须要下划线_
#不指定global|session ,默认session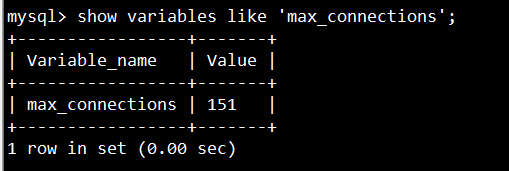
修改系统变量:
启动时加入参数
mysqld --max-connections=1000配置文件
[server] max-connections=1000SET(服务运行时)
GLOBAL 全局
SESSION 会话
服务器在启动时会把每个全局变量设置为默认
语法
set [global|session] option = value; set [@@(global|session).] option = value; #举例 set global default_strage_engine = MyISAM; set @@global.default_strage_engine = MyISAM; set default_strage_engine = MyISAM; #不指定默认session
注意❗:
不是所有的系统变量都有global和session的作用范围,有些只有global,有些只有session,大部分都有
有些系统变量只读,不可修改
状态变量
show global status like ‘Max_used_connections’;
安装
ubuntu
系统:Ubuntu16.04
apt-get update
apt-get install mysql-server需要注意的是,在安装mysql 后是不可以使用navicat等远程工具进行连接的
默认安装后,3306端口只绑定给了localhost,所以外网是无法访问的
解决方法:
vim /etc/mysql/mysql.conf.d/mysqld.cnf将bind-address = 127.0.0.1注释掉

重启即可
systemctl restart mysql
service mysql restart接着授予权限:
centos
系统:centos7
下载mysql5.7的本地仓库文件
wget -i -c http://dev.mysql.com/get/mysql57-community-release-el7-10.noarch.rpm将仓库信息添加至yum
yum -y install mysql57-community-release-el7-10.noarch.rpm接着在通过yum进行安装
yum -y install mysql-community-server --nogpgcheck此时mysql会取代mariadb
启动mysql服务
systemctl start mysqld
systemctl status mysqld此时的登陆密码存放在文件里,查看密码,用该初始化密码登录
grep "A temporary password is generated" /var/log/mysqld.log|awk '{print $11}'
使用命令登录数据库后,修改该默认密码,否则无法使用
ALTER USER 'root'@'localhost' IDENTIFIED BY '$Password';其中,新密码必须使用大写,小写,数字和特殊字符组成
开启远程登录
grant all privileges on *.* to 'root'@'%' identified by 'password' with grant option;
flush privileges; 其中%代表所有ip,password替换为数据库密码。
用户管理
新建用户
creat user 'jayce'@'host' identified by 'password'修改密码
alter user 'jayce'@'host' identified by 'password'权限管理
查看用户权限
show grants for 'root'@'localhost';授予权限
grant privileges on databasename.table to 'username'@'host';revoke privileges on databasename.table to 'username'@'host';Mysql数据类型
整数类型
整数类型一共有 5 种,包括 TINYINT、SMALLINT、MEDIUMINT、INT(INTEGER)和 BIGINT。
| 整数类型 | 字节 | 有符号范围 | 无符号范围 |
|---|---|---|---|
| TINYINT | 1 | -128~127 | 0~255 |
| SMALLINT | 2 | -32768~32767 | 0~65535 |
| MEDIUMINT | 3 | -8388608~8388607 | 0~16777215 |
| INT/INTEGER | 4 | -2147483648~2147483647 | 0~4294967295 |
| BIGINT | 8 | -9223372036854775808~9223372036854775807 | 0~18446744073709551615 |
参数:
括号数值的取值范围是(0, 255)。例如,int(5):当数据宽度小于5位的时候在数字前面需要用字符填满宽度。
ZEROFILL 表示数字前面的字符宽度用0填充,(如果某列是ZEROFILL,那么MySQL会自动为当前列添加UNSIGNED属性)
UNSIGNED表示无符号类型(非负)
TINYINT有符号数和无符号数的取值范围分别为-128~ 127和0~255,由于负号占了一个数字位,因此TINYINT默认的显示宽度为4。同理,其他整数类型的默认显示宽度与其有符号数的最小值的宽度相同。
应用场景
(1)TINYINT :一般用于枚举数据,比如系统设定取值范围很小且固定的场景。
(2)SMALLINT :可以用于较小范围的统计数据,比如统计工厂的固定资产库存数量等。
(3)MEDIUMINT :用于较大整数的计算,比如车站每日的客流量等。
(4)INT、INTEGER :取值范围足够大,一般情况下不用考虑超限问题,用得最多。比如商品编号。
(5)BIGINT :只有当你处理特别巨大的整数时才会用到。比如双十一的交易量、大型门户网站点击量、证券公司衍生产品持仓等。
数据库操作
查看数据库
show databases;选择数据库
use database_name;
set names utf8;查看表
show tables;创建表
CREATE TABLE table_name
(
column_name1 data_type(size),
column_name2 data_type(size),
column_name3 data_type(size)
);
CREATE TABLE Persons
(
PersonID int,
LastName varchar(255),
FirstName varchar(255),
Address varchar(255),
City varchar(255)
);可使用 INSERT INTO 语句向空表写入数据。
约束
在创建表的时候用于规定数据规则,比如NOT NULL
在 SQL 中,我们有如下约束:
NOT NULL
- 指示某列不能存储 NULL 值。在默认的情况下,表的列接受 NULL 值。
UNIQUE
保证某列的每行必须有唯一的值。比如ID等值需要唯一性
语法:
/*MySQL*/
CREATE TABLE Persons
(
P_Id int NOT NULL,
Name varchar(255) NOT NULL,
UNIQUE (P_Id)
);
/*SQL Server / Oracle / MS Access*/
CREATE TABLE Persons
(
P_Id int NOT NULL UNIQUE,
Name varchar(255) NOT NULL,
);- 定义多个列的 UNIQUE 约束:
/*MySQL / SQL Server / Oracle / MS Access:*/
CREATE TABLE Persons
(
P_Id int NOT NULL,
Name varchar(255) NOT NULL,
CONSTRAINT uc_PersonID UNIQUE (P_Id,LastName)
);- 当表已被创建时,如需在 “P_Id” 列创建 UNIQUE 约束,请使用下面的 SQL:
ALTER TABLE Persons ADD UNIQUE (P_Id);- 定义多个列的 UNIQUE 约束:
ALTER TABLE Persons ADD CONSTRAINT uc_PersonID UNIQUE (P_Id,LastName);- 撤销UNIQUE约束
/*MySQL*/
ALTER TABLE Persons
DROP INDEX uc_PersonID
/*SQL Server / Oracle / MS Access*/
ALTER TABLE Persons
DROP CONSTRAINT uc_PersonIDPRIMARY KEY
NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。
主键必须包含唯一的值。
主键列不能包含 NULL 值。
每个表都应该有一个主键,并且每个表只能有一个主键。
/*MySQL*/ CREATE TABLE Persons ( P_Id int NOT NULL, Name varchar(255) NOT NULL, PRIMARY KEY (P_Id) ) /*SQL Server / Oracle / MS Access:*/ CREATE TABLE Persons ( P_Id int NOT NULL PRIMARY KEY, Name varchar(255) NOT NULL, )ALTER TABLE 时的 SQL PRIMARY KEY 约束
当表已被创建时,如需在 “P_Id” 列创建 PRIMARY KEY 约束,请使用下面的 SQL:
/*MySQL / SQL Server / Oracle / MS Access*/ ALTER TABLE Persons ADD PRIMARY KEY (P_Id)如需命名 PRIMARY KEY 约束,并定义多个列的 PRIMARY KEY 约束,请使用下面的 SQL 语法:
/*MySQL / SQL Server / Oracle / MS Access*/ ALTER TABLE Persons ADD CONSTRAINT pk_PersonID PRIMARY KEY (P_Id,LastName)注释:如果您使用 ALTER TABLE 语句添加主键,必须把主键列声明为不包含 NULL 值(在表首次创建时)。
撤销 PRIMARY KEY 约束
如需撤销 PRIMARY KEY 约束,请使用下面的 SQL:
/*MySQL*/ ALTER TABLE Persons DROP PRIMARY KEY /*SQL Server / Oracle / MS Access*/ ALTER TABLE Persons DROP CONSTRAINT pk_PersonID ALTER TABLE Persons DROP CONSTRAINT P_Id
FOREIGN KEY
一个表中的 FOREIGN KEY 指向另一个表中的 UNIQUE KEY(唯一约束的键)。保证一个表中的数据匹配另一个表中的值的参照完整性。
外键的解释:一个表中的某一列为外键,与另一个表的唯一约束键(UNIQUE KEY)
FOREIGN KEY 约束用于预防破坏表之间连接的行为。
FOREIGN KEY 约束也能防止非法数据插入外键列,因为它必须是它指向的那个表中的值之一
/*MySQL*/ CREATE TABLE Orders ( O_Id int NOT NULL, OrderNo int NOT NULL, P_Id int, PRIMARY KEY (O_Id), FOREIGN KEY (P_Id) REFERENCES Persons(P_Id) ) /*SQL Server / Oracle / MS Access*/ CREATE TABLE Orders ( O_Id int NOT NULL PRIMARY KEY, OrderNo int NOT NULL, P_Id int FOREIGN KEY REFERENCES Persons(P_Id) )
CHECK
保证列中的值符合指定的条件。
DEFAULT
规定没有给列赋值时的默认值。
AUTO INCREMENT
自增
CREATE TABLE Persons
(
ID int NOT NULL AUTO_INCREMENT,
PRIMARY KEY (ID)
)可使id自增
修改起始值
ALTER TABLE Persons AUTO_INCREMENT=100修改表
修改字段
请注意,修改字段可能会影响到已经存在的应用程序或查询,因此应该在进行此操作之前备份数据表。
新增
ALTER TABLE table_name ADD column_name data_type;新增指定位置
ALTER TABLE table_name ADD column_name data_type AFTER existing_column;修改
ALTER TABLE table_name MODIFY column_name new_data_type;其中,table_name是要修改的表名,column_name是要修改的字段名,new_data_type是新的数据类型。
重命名
ALTER TABLE table_name RENAME COLUMN old_column_name TO new_column_name;删除
ALTER TABLE table_name DROP column_name;其中table_name是要修改的表名,column_name是要删除的字段名。
查看表结构
describe table_name;
desc table_name;
#或
show create table SALGRADE;查询
当数据量大的时候,数据量会刷屏,使用pager less 可以切换less模式,除了pager less,还有pager more,pager awk、pager wc -l(统计行数)等,直接使用查询,可生效
语法:
SELECT [字段],[字段] FROM [表名];
SELECT * FROM student;去重
SELECT DISTINST
返回唯一不同的值,可理解为不重复
与select使用方法一样,DISTINCT 关键字只能在 SELECT 语句中使用。
如果 DISTINCT 关键字后有多个字段,则会对多个字段进行组合去重,也就是说,只有多个字段组合起来完全是一样的情况下才会被去重。就是逻辑与的关系,两个字段都要一样才能被去除
SELECT DISTINCT name,age FROM student;LIMIT
用于返回规定要返回记录的数目
注意:。MySQL 支持 LIMIT 语句来选取指定的条数数据, Oracle 可以使用 ROWNUM 来选取。
SELECT [column_name] FROM [table_name] LIMIT [number];
SELECT * FROM websites LIMIT 2;输出前两个指定初始位置
SELECT * FROM websites LIMIT 2,6;
#指定第三个开始的后六个
#LIMIT 后的两个参数必须都是正整数。数据类型
正则表达式
%类似于*_下划线表示一个字符;M%: 为能配符,正则表达式,表示的意思为模糊查询信息为 M 开头的。%M%: 表示查询包含M的所有内容。%M_: 表示查询以M在倒数第二位的所有内容。
SQL [charlist]
MySQL中使用 REGEXP 或 NOT REGEXP 运算符 (或 RLIKE 和 NOT RLIKE) 来操作正则表达式
SELECT * FROM Websites WHERE name REGEXP '^[GFs]';正则表达式不区分大小写,如果需要区分,则加上 BINARY 关键字
SELECT * FROM table WHERE name REGEXP (BINARY) 'jayce';常规的三个:(如果设置了RegExp 对象的 Multiline 属性,$ 也匹配 ‘\n’ 或 ‘\r’ 之前的位置。)
^ 匹配输入字符串的开始位置。
$ 匹配输入字符串的结束位置。
* 匹配 0 次或多次。
-- 查找name字段中以'st'为开头的所有数据:
SELECT name FROM person_tbl WHERE name REGEXP '^st';
-- 查找name字段中以'ok'为结尾的所有数据:
SELECT name FROM person_tbl WHERE name REGEXP 'ok$';
-- 查找name字段中包含'mar'字符串的所有数据:
SELECT name FROM person_tbl WHERE name REGEXP 'mar';
-- 查找name字段中以'mar' 结尾并以任何前缀开头
SELECT name FROM person_tbl WHERE name REGEXP '.*mar';星号可用于与字符匹配 0 次或多次。例如,REGEXP '.*abc' 匹配的字符串以 abc 结尾并以任何前缀开头。因此,aabc、xyzabc 和 abc 匹配,但 bc 和 abcc 则不匹配。
. 匹配除 “\n” 之外的任何单个字符。要匹配包括 ‘\n’ 在内的任何字符,请使用像 ‘[.\n]’ 的模式
例如:
SELECT name FROM person_tbl WHERE name REGEXP '.*mar';
SELECT name FROM person_tbl WHERE name REGEXP '[*mar]';但是不可以写成:'*mar*'
+ 匹配前面的子表达式一次或多次。
加号可用于与字符匹配 1 次或多次。例如,
'bre+'匹配 bre 和 bree,但不匹配 br。
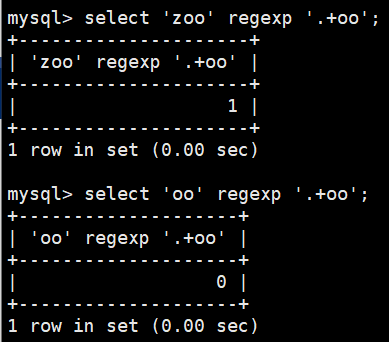
意思就是刚好匹配还不行,必须前面多一个
| 元字符 | 说明 |
|---|---|
| * | 匹配它前面的零个或多个子表达式,0个或多个匹配,效果与{0,}—致 |
| + | 匹配它前面的一个或多个子表达式,1个或多个匹配,效果与{1,}一致 |
| ? | 匹配它前面的零个或一个子表达式,1个或0匹配,效果与{0,1}一致 |
| {n} | 等于n个匹配数目 |
| {n,} | 大于等于n个匹配 |
| {n,m} | 大于等于n小于等于m个, m<255 |
[] 字符集合。匹配所包含的任意一个字符
SELECT * FROM runoob_test_tbl WHERE runoob_author REGEXP '[OB]';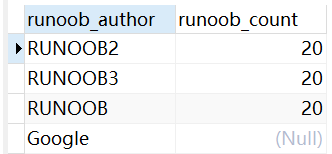
[^...] 负值字符集合。匹配未包含的任意字符。
SELECT * FROM runoob_test_tbl WHERE runoob_author REGEXP '[^RUNOOB]';结果:
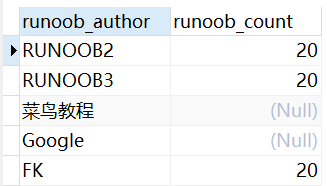
结果发现RUNOOB并没有出现,原因是[^RUNOOB]过滤掉了RUNOOB
p1|p2|p3 匹配 p1 或 p2 或 p3。例如,’z|food’ 能匹配 “z” 或 “food”。’(z|f)ood’ 则匹配 “zood” 或 “food”。
| 模式 | 描述(具体匹配什么) |
|---|---|
| . | 匹配除 “\n” 之外的任何单个字符。 |
| [abc] | 匹配方括号之间列出的任何字符。 |
| [^abc] | 匹配方括号之间未列出的任何字符。 |
| [A-Z] | 匹配任何大写字母。 |
| [a-z] | 匹配任何小写字母。 |
| [0-9] | 匹配从0到9的任何数字。 |
| [[:<:]] | 匹配单词的开头。 |
| [[:>:]] | 匹配单词的结尾。 |
| [:class:] | 匹配字符类,即[:alpha:]匹配字母,[:space:]匹配空格,[:punct:]匹 |
| 配标点符号 | ,[:upper:] 匹配上层字母。 |
正则表达式测试
可以在不使用数据库表的情况下用 SELECT 语句来测试正则表达式,REGEXP 检查总是返回0(没有匹配)或1(匹配)。可以用带文字串的 REGEXP 来测试表达式,并试验它们。
SELECT 'Hern' REGEXP '[0-9]';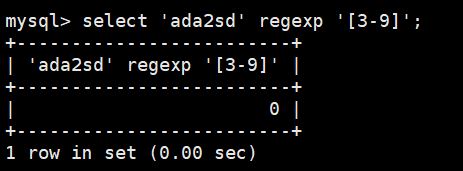
条件查询
WHERE
用于提取满足条件的记录
SELECT [字段],[字段] FROM [表名] WHERE [字段] operator value;其中文本字段需要使用单引号
但where不一定非要运算符
where 0 会返回一个空值
where 1 相当于没有这句,因为每一行记录都返回true
HAVING
HAVING 关键字和 WHERE 关键字都可以用来过滤数据,且 HAVING 支持 WHERE 关键字中所有的操作符和语法。
区别,where是挑选符合条件的查询,having是先全查出来再过滤。
运算符
算数运算符
+ - * / div mod %取余
当数值与字符串加时,会转换字符串为数值,转不了的转成0
100 + ‘1’ =101 100 + ‘a’ =100
比较运算符
| 运算符 | 描述 | 语法 |
|---|---|---|
| = | 等于 | |
| <=> | 安全等于,可以判断null | |
| <> | 不等于。注释:在 SQL 的一些版本中,该操作符可被写成 != | |
| > | 大于 | |
| < | 小于 | |
| >= | 大于等于 | |
| <= | 小于等于 | |
| BETWEEN | 在某个范围内 | where [字段] between value1 and value2; |
| IN | 指定针对某个列的多个可能值 | where sal in (5000,3000,1500); |
| AND | 与,同时满足两个条件 | where sal > 2000 and sal < 3000; |
| OR | 或,满足其中一个条件的值 | |
| NOT | 非 满足不包含该条件的值 | where not sal > 1500; == sal>=1500 |
| is null | 查询空值 | |
| LIKE | 搜索某种模式 | where ename like ‘M%’;内容有M的 |
- % 表示多个字值,
- _ 表示一个字符;
- M% : 为能配符,正则表达式,表示的意思为模糊查询信息为 M 开头的。
- %M% : 表示查询包含M的所有内容。
- %M_ : 表示查询以M在倒数第二位的所有内容。
只要null参与,结果就为null
逻辑运算符
逻辑运算可以集合起来
SELECT * FROM Websites WHERE alexa > 15 AND (country='CN' OR country='USA');逻辑运算的优先级:
() not and or
XOR:记录满足其中一个条件,并且不满足另一个条件时,才会被查询出来
排序
ORDER BY
语法:
SELECT * FROM Websites ORDER BY alexa;默认按照升序排列(ASC)
降序:
SELECT * FROM Websites ORDER BY alexa DESC;别名
SQL
将表名称或列名称指定别名,创建别名让列名称可读性更强
SELECT column_name AS alias_name FROM table_name;
SELECT column_name FROM table_name AS alias_name;别名有三种方式,直接写、as、双引号(不要写单引号)
SELECT column_name alias_name FROM table_name;
SELECT column_name AS alias_name FROM table_name;
SELECT column_name "alias name" FROM table_name;将多列结合一起:
SELECT name, CONCAT(url, ', ', alexa, ', ', country) AS site_info FROM websites;对表使用别名:
SELECT w.name FROM websites as w WHERE w.name='Google';SELECT w.name, w.url, a.count, a.date FROM Websites AS w, access_log AS a WHERE a.site_id=w.id and w.name="菜鸟教程";在下面的情况下,使用别名很有用:
- 在查询中涉及超过一个表
- 在查询中使用了函数
- 列名称很长或者可读性差
- 需要把两个列或者多个列结合在一起
分组
group by
多个字段分组时,先按照字段顺序依次分组,如果前一个字段有重复,才会进行后续分组
GROUP CONCAT
GROUP_CONCAT() 函数会把每个分组的字段值都显示出来。
SELECT `sex`, GROUP_CONCAT(name) FROM tb_students_info GROUP BY sex;女 Henry,Jim,John,Thomas,Tom
男 Dany,Green,Jane,Lily,Susan
GROUP BY 关键字经常和聚合函数一起使用。
聚合函数包括 COUNT(),SUM(),AVG(),MAX() 和 MIN()。
WITH ROLLUP
WITH POLLUP 关键字用来在所有记录的最后加上一条记录,这条记录是上面所有记录的总和,即统计记录数量。
连接
(JOIN)
sql join用于将两个表结合起来
下图展示了 LEFT JOIN、RIGHT JOIN、INNER JOIN、OUTER JOIN 相关的 7 种用法。
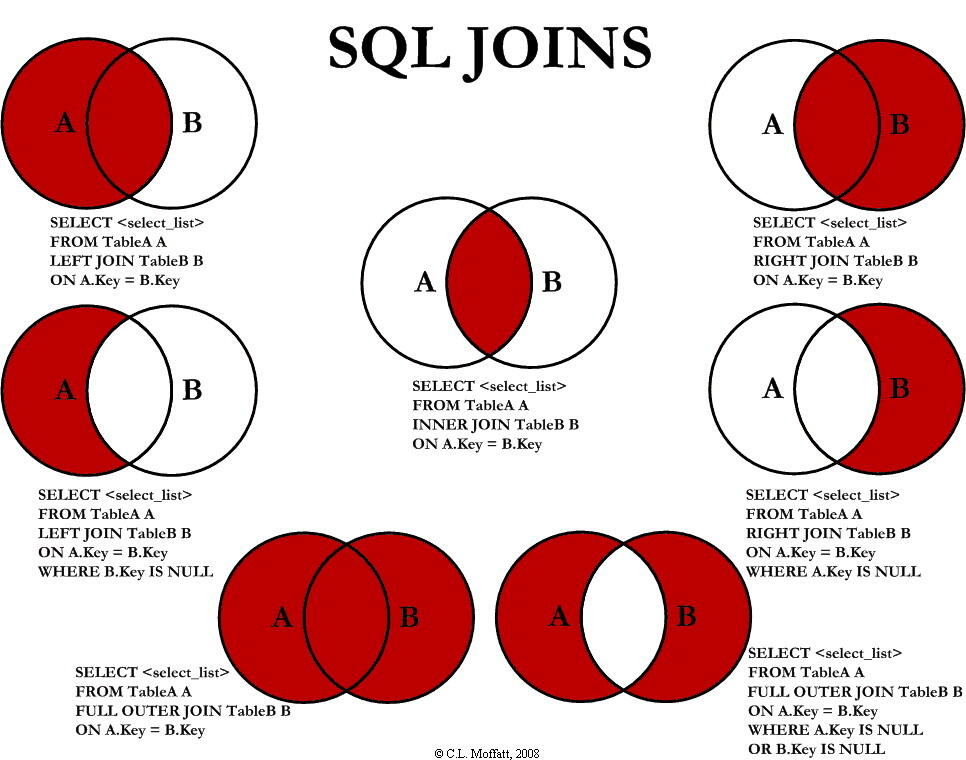
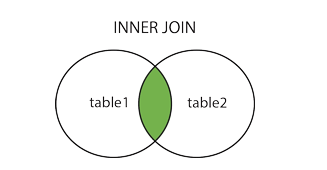
INNER JOIN
在表中存在至少一个匹配
SELECT column_name FROM table1 INNER JOIN table2 ON table1.column_name=table2.column_name;
SELECT column_name FROM table1 JOIN table2 ON table1.column_name=table2.column_name;INNER JOIN 与JOIN相同
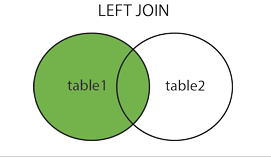
LEFT JOIN
从左表返回所有的行,如果右表没有匹配,结果为NULL
RIGHT JOIN
从右表返回所有的行,如果左表没有匹配,结果为NULL
FULL OUTER JOIN
只要左右表中存在一个表匹配,则返回行
FULL OUTER JOIN 关键字结合了 LEFT JOIN 和 RIGHT JOIN 的结果。
SELECT column_name(s) FROM table1 FULL OUTER JOIN table2 ON table1.column_name=table2.column_nameSQL UNION
UNION操作符合并两个以上SELECT语句
请注意,UNION 内部的每个 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每个 SELECT语句中的列的顺序必须相同。
子查询
SELECT name FROM tb_students_info WHERE course_id IN (SELECT id FROM tb_course WHERE course_name = 'Java');需要注意的是,只出现在子查询中而没有出现在父查询中的表不能包含在输出列中。
#错误
SELECT * FROM (SELECT * FROM result)
#z
SELECT * FROM (SELECT * FROM result) AS Temp;NULL
- IS NULL: 当列的值是 NULL,此运算符返回 true。
- IS NOT NULL: 当列的值不为 NULL, 运算符返回 true
- <=>: 比较操作符(不同于 = 运算符),当比较的的两个值相等或者都为 NULL 时返回 true。只比较NULL
**不能使用 = NULL 或 != NULL 在列中查找 NULL 值 **
注意:
select * , columnName1+ifnull(columnName2,0) from tableName;columnName1,columnName2 为 int 型,当 columnName2 中,有值为 null 时,columnName1+columnName2=null,
空值参与运算
空值参与运算,结果为空,可使用ifnull函数解决
ifnull(columnName2,0)把 columnName2 中 null 值转为 0。
SELECT 1 + IFNULL(LOSAL,0) FROM SALGRADE;着重号
在表名,字段等与数据库保留字冲突时使用
``查看所有表大小和记录
SELECT concat_ws('.',a.table_schema ,a.table_name),
CONCAT(ROUND(table_rows)) AS 'Number of Rows',
CONCAT(ROUND(data_length/(1024*1024),4),',') AS 'data_size',
CONCAT(ROUND(index_length/(1024*1024),4),'M') AS 'index_size',
CONCAT(ROUND((data_length+index_length)/(1024*1024),4),'M') AS'Total'
FROM
information_schema. TABLES a
WHERE
a.table_schema = 'j' order by CAST(Total AS SIGNED);插入
INSERT INTO
第一种形式,无需指定列名,只需提供被插值
INSERT INTO Websites (name, url, alexa, country) VALUES ('百度','https://www.baidu.com/','4','CN');如果不指定列名,需要将values全部按顺序列出
insert into select 和select into from
insert into scorebak select * from socre where neza='neza' --插入一行,要求表scorebak 必须存在
select * into scorebak from score where neza='neza' --也是插入一行,要求表scorebak 不存在更新
UPDATE
UPDATE [table_name] SET column1=value1,column2=value2,... WHERE some_column=some_value;Update 警告!
在更新记录时要格外小心!在上面的实例中,如果我们省略了 WHERE 子句,如下所示:
UPDATE Websites
SET alexa='5000', country='USA'执行以上代码会将 Websites 表中所有数据的 alexa 改为 5000,country 改为 USA。
!!!!执行没有 WHERE 子句的 UPDATE 要慎重,再慎重。!!!!
删除
DELETE
DELETE FROM [table_name] WHERE [some_column=some_value];删除行
表复制
INSERT INTO SELECT
INSERT INTO SELECT 语句从一个表复制数据,然后把数据插入到一个已存在的表中。目标表中任何已存在的行都不会受影响。
复制希望的列插入到另一个已存在的表中
INSERT INTO table2 (column_name(s)) SELECT column_name(s) FROM table1;
INSERT INTO Websites (name, country) SELECT app_name, country FROM apps;数据导入导出
mysqldump
| 参数名 | 缩写 | 含义 |
|---|---|---|
| –host | -h | 服务器IP地址 |
| –port | -P | 服务器端口号 |
| –user | -u | MySQL 用户名 |
| –pasword | -p | MySQL 密码 |
| –databases | 指定要备份的数据库 | |
| –all-databases | 备份mysql服务器上的所有数据库 | |
| –compact | 压缩模式,产生更少的输出 | |
| –comments | 添加注释信息 | |
| –complete-insert | 输出完成的插入语句 | |
| –lock-tables | 备份前,锁定所有数据库表 | |
| –no-create-db/–no-create-info | 禁止生成创建数据库语句 | |
| –force | 当出现错误时仍然继续备份操作 | |
| –default-character-set | 指定默认字符集 | |
| –add-locks | 备份数据库表时锁定数据库表 | |
| –single-transaction | 必加 | 备份时不影响数据库运行 |
备份所有数据库:
mysqldump -uroot -p --all-databases >/all.dboutfile & infile
outfile
语法:
select * from table into outfile '/dic/dic/file' fields terminated by '|'fields terminated by '|'代表以竖线分隔,默认为空格分隔
注意,不是这里涉及到输出限制,查询secure_file_priv参数,看看mysql可以输出到哪里
ERROR 1290 (HY000): The MySQL server is running with the –secure-file-priv option so it cannot execute this statement
show global variables like '%secure_file_priv%';secure_file_priv 为 NULL 时,表示限制mysqld不允许导入或导出。
secure_file_priv 为 /tmp 时,表示限制mysqld只能在/tmp目录中执行导入导出,其他目录不能执行。
secure_file_priv 没有值时,表示不限制mysqld在任意目录的导入导出。
secure_file_priv 参数是只读参数,不能使用set global命令修改。
infile
语法:
load data infile '/dic/dic/file' into table database_name.tablename fields terminated by '|'视图
视图是可视化的表,视图包含行和列,就像一个真实的表。视图中的字段就是来自一个或多个数据库中的真实的表中的字段。
创建视图
CREATE VIEW view_name AS SELECT column_name(s) FROM table_name WHERE condition例子:
创建关于销售员的职工表
总职工:
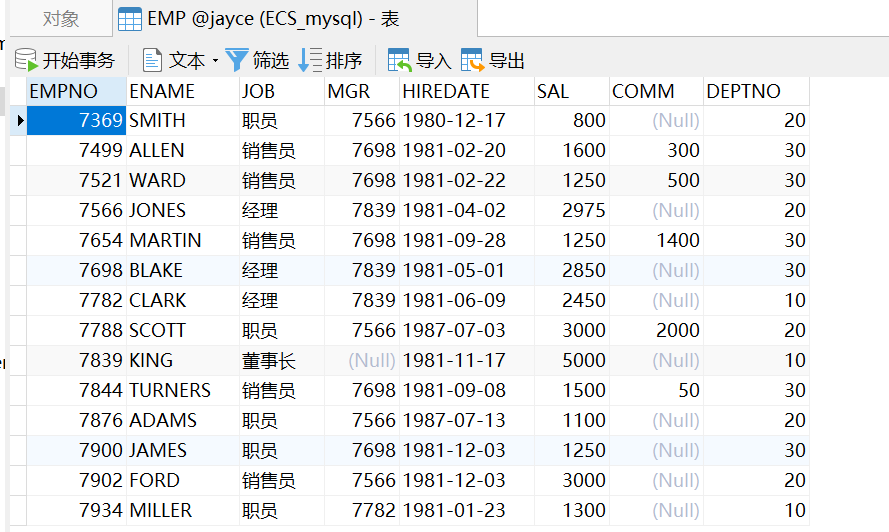
CREATE VIEW sell AS SELECT * FROM `EMP` WHERE JOB="销售员";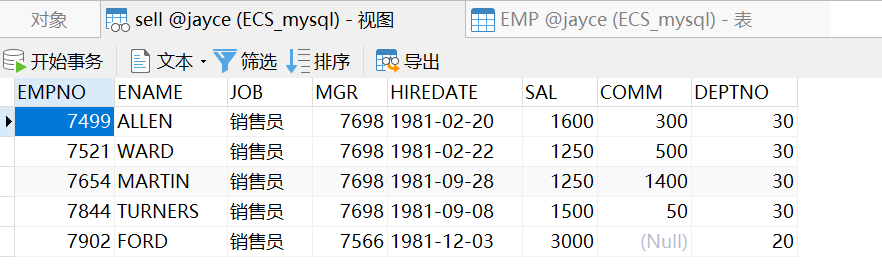
更新视图
CREATE OR REPLACE VIEW view_name AS
SELECT column_name(s)
FROM table_name
WHERE condition索引
索引是一张表,该表保存了主键与索引字段,并指向实体表的记录。类似于字典的目录。
分类
单列索引
普通索引
MySQL中基本索引类型,没有什么限制,允许在定义索引的列中插入重复值和空值,纯粹为了查询数据更快一 点。
唯一索引
索引列中的值必须是唯一的,但是允许为空值。
主键索引
是一种特殊的唯一索引,不允许有空值。(主键约束,就是一个主键索引)。
组合索引
在表中的多个字段组合上创建的索引,只有在查询条件中使用了这些字段的左边字段时,索引才会被使用,使用组合索引时遵循最左前缀集合。
全文索引
只有在MyISAM引擎上才能使用,只能在CHAR,VARCHAR,TEXT类型字段上使用全文索引,介绍了要求,说说什么是全文索引,就是在一堆文字中,通过其中的某个关键字等,就能找到该字段所属的记录行。
创建索引
普通索引
直接创建
CREATE INDEX indexName ON table_name (column_name)修改表结构
ALTER table tableName ADD INDEX indexName(columnName)创建表的时候直接指定
CREATE TABLE mytable( ID INT NOT NULL, username VARCHAR(16) NOT NULL, INDEX [indexName] (username(length)) );



