Linux
注意
不要再服务器访问高峰运行高负载命令
远程配置防火墙时不要把自己踢出防火墙
合理分配权限
定时备份数据和日志
文件
链接
软连接:类似于快捷方式
硬链接:类似于拷贝,相比于cp -p 两个文件可以同时更新
删除源文件后,软连接不可访问,硬链接可以继续访问
硬链接不可以操作目录
如何判断是否是硬链接:
查看i节点,一个i节点会映射到多个文件
目录作用
| 目录名 | 作用 |
|---|---|
| /bin | 存放系统命令 |
| /sbin | 保存和系统环境设置相关的命令 |
| /usr/bin | 存放系统命令,区别是单用户模式下不能执行 |
| /usr/sbin | 存放根文件系统不必要的系统管理命令 |
| /boot | 系统启动目录 |
| /dev | 设备文件 |
| /etc | 配置文件 |
| /home | 家目录 |
| /lib | 系统调用函数库保存位置 |
| /lost+found | 根分区备份恢复目录 |
| /media | 挂载目录,系统建议只挂载媒体设备 |
| /mnt | 挂载目录,硬盘,U盘 |
| /misc | 挂载目录,建议挂载NFS服务 |
| /opt | 第三方安装软件保存位置 |
| /prco | 虚拟文件系统,数据不会存在硬盘中 |
| /sys | 和prco相似,主要保存内核信息 |
| /root | |
| /srv | 服务数据目录 |
| /tmp | 临时目录,存放临时文件 |
| /usr | 系统软件资源目录 |
| /var | 动态数据保存位置 |
挂载目录类似于Windows的盘符
文件传输
scp
scp [-1246BCpqrv] [-c cipher] [-F ssh_config] [-i identity_file]
[-l limit] [-o ssh_option] [-P port] [-S program]
[[user@]host1:]file1 [...] [[user@]host2:]file2简易
scp file root@ip:folder
#或者
scp file root@ip:file
#或者
scp file ip:folder
#或者
scp file ip:file 指定了远程的目录,文件名字不变,指定文件名,则传输后重命名
传输文件夹使用 -r 参数,文件夹会传输到指定的目录下,而不是重命名
例如
scp -r /root/shell 172.0.0.1:/root/linux/ 将本地 shell目录复制到远程 linux目录下 /root/linux/shell
相关参数:
-P 指定端口号
-i 使用密钥文件登录
scp -i key.pem /root/file ip:dic 终端
物理终端
直接接入本机
虚拟终端
在物理终端商软件虚拟实现的终端,centos6 有默认6个虚拟终端
Ctrl + Alt + Fn (n = 1-6)
设备文件路径:/dev/tty#
模拟终端
图形界面打开的命令行、ssh、telnet
设备文件路径:/dev/pts/# 无穷个
查看终端设备tty
命令提示符
prompt[root@localhost ~]#
[root@localhost ~] : PS1
prompt:
管理员:#
普通用户:$
系统分区
主分区
最多只能有4个
扩展分区
当主分区不够时,拿出一个分区做扩展分区
扩展分区最多只能有1个
主分区加扩展分区最多有4个
不能写入数据,不能格式化,只能包含逻辑分区
逻辑分区
可以写入数据,
格式化
高级格式化,又称逻辑格式化,它指根据用户选定的文件系统(FAT32,NTFS,EXT2,3,4)
linux默认EXT4格式会把分区变成一个一个等大小的数据块,每个数据块为4kb
文件有一个inode号,文件读取通过这个编号去硬盘分区数据块后找
挂载
权限
文件权限:r读,w写,x执行
rw- r– r–
u g o
u所有者 g所属组 o 其他人
权限够用就行,除了可执行文件(脚本等),不需要执行权限
| 字符 | 权限 | 对文件含义 | 对目录含义 | 文件操作 | 目录操作 |
|---|---|---|---|---|---|
| r | 读 | 查看文件内容 | 列出目录内容 | cat、tail、less.. | ls |
| w | 写 | 修改文件 | 目录中创建、删除文件 | vim | touch 、mkdir、rm |
| x | 执行 | 进入目录,执行文件 | 进入目录 | bash等 | cd |
对文件的删除权限其实要看所属目录的权限是否有写权限
命令
输入命令,回车:
shell程序找到键入命令所对应的可执行程序或代码,并由其分析后提交给内核分配资源将其运行起来。表现为一个或多个进程。
在shell中可执行的命令有两类:
内建命令:由shell自带的,而且通过某命令形式提供;
外部命令:在当前系统的某文件系统路径下有对应的可执行程序文件:
which, whereis
区别内部或外部命令:
type COMMAND
shell 程序可搜寻的执行文件的路径定义在PATH环境变量中:
ehco $PATH 
自左至右依次查询,查到停止
shell搜寻代外部命令的路径结果会缓存至kv(key-value)存储中:
可用命令hash命令查看
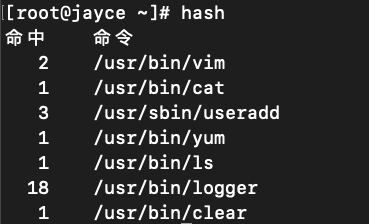
缓存副作用:
如果命令位置发生了转移,系统还是会按缓存路径运行,导致命令失效
mv /bin/ls /usr/bin/ls
ls
# -bash: /bin/ls: NO such file or directory清除缓存:
hash -d [command] #删除一个命令缓存
hash -r #删除所有缓存连接
linux&macos
ssh username@ip -p:指定端口
使用私钥登陆:
ssh -i ~/.ssh/jayce username@ip文件
关机与重启
shutdown
立即关机:
shutdown -h now延迟一分钟关机
shutdown -h 1halt
直接关机
reboot
重启系统
sync
将内存的数据同步到磁盘
作用:关机和重启之前执行。放止数据丢失
登陆和注销
登陆少用root账号登陆,可避免操作失误。
可使用普通用户登陆,再用su -用户名切换系统管理员身份
logout
注销
logout在图形运行级别无效,在运行级别3下有效
运行级别
linux有7个运行级别
0:关机
1:单用户(可找回密码,不需要密码)
2:多用户无网络
3:多用户有网络
4:保留
5:图形界面
6:重启
常用的是3和5
运行级别配置文件:/etc/inittab (centos7以前)
在配置文件中修改运行级别
切换指定运行级别
基本语法
init [012356]
用户管理
用户组
系统可以对有共性的多个用户进行统一的管理
每个用户至少属于一个组
比如root属于root组
增加删除组
groupadd
groupdel家目录
home目录下有各个用户的家目录
当用户登陆时,会自动进入自己的家目录
/home/jayce添加用户
useradd
useradd -d /home/jayce -m jayce-d : 指定用户目录
-m : 如果目录为空,则新建
-g:指定用户组
passwd设置密码
passwd jayce在创建好用户后要设置密码
删除用户
userdel默认加用户名是不会删除其所有文件的
-f :强制删除,即时已经登陆
-r:连同相关用户文件一起删除
另一种方法:
进入/etc/passwd中,删除用户记录
⚠️不安全
修改用户的组
usermod
usermod -g usergroup username查看用户
id username切换用户
su - username从高权限到低权限不需要密码
返回root用exit
查看当前用户
who am i = whoami
用户信息存放
用户配置文件:/etc/passwd
- 用户名:密码(加密在shadow):用户id:组id::家目录:对应的shell
- 组配置文件:/etc/group
- 组名:口令:组id:列表(看不到)
- 口令配置文件:/etc/shadow
- 加密文件存放密码
常用指令
man
查看指令手册
/usr/share/manman1—man9
有多个man的目的是为了区分权限
man1 用户命令
man2 系统调用
man3 c库调用
man4 设备及特殊文件
man5 配置文件格式
man6 游戏
man7 杂项
man8 管理类命令
有些关键字在不止一个章节中
指导章节:man # [COMMAND]
man`命令配置文件`/etc/man.config MANPATH /.../.../...
操作方法
Space,向文件尾翻屏:
b,向文件首部翻屏:
d,向文件尾部翻半屏:
u,向文件首部翻半屏:
RETURN,向文件尾部翻一行
y ,向文件首部翻一行
q ,退出
p
wd
查看当前位置的绝对路径
ls
-a 显示所有文件包括隐藏
-l以列表的形式

d:目录 -:文件 l:软连接
-h humman人性化,字节大小带上单位
-d 显示目录本身

-i 查询文件号
ln
创建链接
软连接:类似于快捷方式
硬链接:类似于拷贝,相比于cp -p 两个文件可以同时更新
删除源文件后,软连接不可访问,硬链接可以继续访问
-s soft 软连接
ln `-s` [源文件] [目标文件]mkdir
创建目录
-p 创建多级目录
rmdir
删除空目录
rm
-r递归删除
-f 强制删除
cp
cp 1.txt /home -r 递归复制
-p 保留文件属性,不会更改修改文件时间
\cp强制覆盖复制,不需要单独确认
mv
移动或重命名
移动:
mv /home/pig.txt /root重命名:
mv oldname newnametouch
新建文件 如果文件名中间需要空格,则必须用双引号
touch "program files"但尽量不要用空格作为文件名,很麻烦
cat
查看文件内容
-n 显示行号
与cat相反的显示方法:tac
配合 | more 按页显示文本内容
more
- space 向下翻页
- enter 向下翻行
- q 退出
- ctrl F 向下滚一屏
- ctrl B 返回上一屏
- = 输出当前行号
- :f 输出文件名和当前行号
less
功能与more类似,但比more强大
less在显示文件内容时,根据显示需要进行加载内容,对大型文件有较高效率
- space 向下翻页
- enter 向下翻行
- q 退出
- pageup
- pagedown
- /字串 向下搜寻【字串】功能:n:向下查找:N:向上查找
- ?字串 向上搜寻【字串】功能:n:向上查找:N:向下查找
chmod
语法:
chmod [{ugoa}{+-=}{rwx}][文件/目录]
chmod [mode=421][文件/目录]
chmod -R 递归修改u(所有者) g(所属组) o(其他人) a(所有人)
+(增加) -(减少) =(赋予)
例如:
chmod u+x,o-r start.sh
chmod (-R) 765 start.shecho
>和>>
>输出重定向
>>追加
history
记录历史操作
登陆shell时,会读取命令历史文件中记录下来的命令: ~/.bash_history
登陆进shell后,新执行的命令只会记录在缓存中
登出shell后,会被追加至记录里
-a更新历史记录文件-d删除历史记录命令history -d 100-c清空命令历史记录
快捷操作:
!100 运行第100行历史记录的命令
!string 调用历史中最近一个以string开头的命令
!! 重复运行上一条命令
find
find命令是根据文件的属性进行查找
- 文件名(-name)
- 文件大小(-size)
- 所有者(-user)
- 所属组(-group)
- 是否为空(-empty)
- 时间,time为日期(天),min为分钟,只有这两种
atime:访问时间(access time),指的是文件最后被读取的时间,可 以使用touch命令更改为当前时间; ctime:变更时间(change time),指的是文件本身最后被变更的时 间,变更动作可以使chmod、chgrp、mv等等; mtime:修改时间(modify time),指的是文件内容最后被修改的时间,修改动作可以使echo重定向、vi等等;
文件名查找
find / -name httpd.conf在根目录下查找文件httpd.conf,表示在整个硬盘查找
find /etc -name httpd.conf在/etc目录下文件httpd.conf
find /etc -name '*srm*'使用通配符*(0或者任意多个)。表示在/etc目录下查找文件名中含有字符串‘srm’的文件*
find . -name 'srm*'表示当前目录下查找文件名开头是字符串‘srm’的文件
文件特征查找
find / -amin -10查找在系统中最后10分钟访问的文件(access time)
find / -atime -2查找在系统中最后48小时访问的文件
find / -empty查找在系统中为空的文件或者文件夹
find / -group cat查找在系统中属于 group为cat的文件
find / -mmin -5查找在系统中最后5分钟里修改过的文件(modify time)
find / -mtime -1查找在系统中最后24小时里修改过的文件
find / -user jayce查找在系统中属于jayce这个用户的文件
find / -size +10000c查找出大于10000000字节的文件
(c:字节,w:双字,k:KB,M:MB,G:GB)
find / -size -1000k查找出小于1000KB的文件
混合查找方式
参数有:!,-and(-a),-or(-o)。
find /tmp -size +10000c -and -mtime +2在/tmp目录下查找大于10000字节并在最后2分钟内修改的文件
find / -user fred -or -user jayce在
/目录下查找用户是fred或者jayce的文件文件find /tmp ! -user jayce在
/tmp目录中查找所有不属于jayce用户的文件
which
查看可执行文件的位置 ,只有设置了环境变量的程序才可以用
whereis
寻找特定文件,只能用于查找二进制文件、源代码文件和man手册页
locate
配合数据库查看文件位置 ,详情:locate -h查看帮助信息
cut
显示每行内容
由此可以实现提取每一行的第n个字符
参数:
-b 以字节为单位进行分割
-c 以字符为单位进行分割
-d 自定义分隔符
-f 与-d一起使用,指定显示哪个区域
实例:
cut -d "%" -f 1以%为分隔符,截取百分号前面的数值 -f 取截取后的第一行
alias
alias 可以为命令指定别名,所谓别名可以省去一长串命令的麻烦
查看别名
直接使用命令alias可以查看所有的别名,如果想看某一命令,在alias后跟命令即可
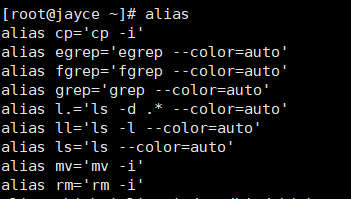
创建别名
例如:
alias newcmd='cmd'
alias install='sudo apt-get install'上述方式一旦关闭终端,设置的别名就失效了
可以将命令放入 /.bashrc 中,当每个进程生成时,都要执行`/.bashrc`中的命令
删除别名
unalias 命令可以将之前的别名删除
unalias vi使用-a参数可以清除所有的别名
不使用别名
当我们为命令加上日常参数后,但有时需要使用原始的命令时,有三种方法可以调用原始命令
- 使用命令的绝对路径
- 切换命令所在目录,使用
./cmd - 在命令前使用反斜线
\
别名永久生效
我们通过 alias 命令设置的别名,仅限于在当前的 Shell 中使用,如果系统重启了,那么新设置的别名就失效了。
如果想让别名永久有效的话,就需要把所有的别名设置方案加入到($HOME)目录下的 .alias 文件中(如果系统中没有这个文件,你可以创建一个),然后在 .bashrc 文件中增加这样一段代码:
# Aliases
if [ -f ~/.alias ]; then
. ~/.alias
fi.alias文件:
vim .alias
######
alias tf='tail -f' #动态查看文件变化执行source ~/.bashrc
top
Linux top命令用于实时显示 process 的动态。
参数说明
d : 改变显示的更新速度,或是在交谈式指令列( interactive command)按 s
q : 没有任何延迟的显示速度,如果使用者是有 superuser 的权限,则 top 将会以最高的优先序执行
c : 切换显示模式,共有两种模式,一是只显示执行档的名称,另一种是显示完整的路径与名称
S : 累积模式,会将己完成或消失的子进程 ( dead child process ) 的 CPU time 累积起来
s : 安全模式,将交谈式指令取消, 避免潜在的危机
i : 不显示任何闲置 (idle) 或无用 (zombie) 的进程
n : 更新的次数,完成后将会退出 top
top -n 3b : 批次档模式,搭配 “n” 参数一起使用,可以用来将 top 的结果输出到档案内
输出到文件
top -n 1 -b > top.txt
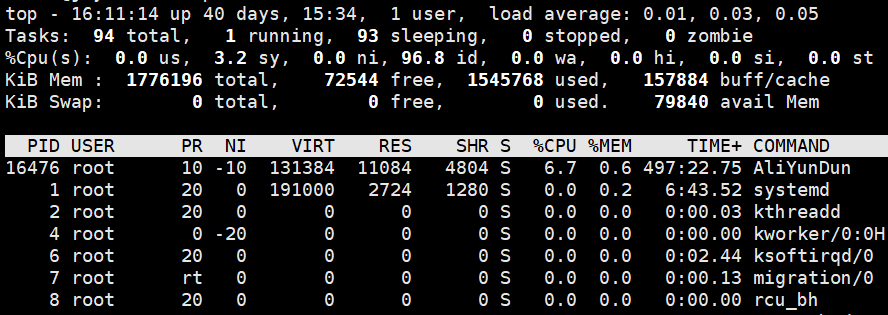
各行解析
top - 16:11:14 up 40 days, 15:34, 1 user, load average: 0.01, 0.03, 0.05
Tasks: 94 total, 1 running, 93 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 3.2 sy, 0.0 ni, 96.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 1776196 total, 72544 free, 1545768 used, 157884 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 79840 avail Mem
第一行
| 内容 | 含义 |
|---|---|
| 16:11:14 | 表示当前时间 |
| up 40days,15:34 | 系统运行时间 不指定格式为时:分 |
| 1 users | 当前登录用户数 |
| load average: 0.01, 0.03, 0.05 | 系统负载,即任务队列的平均长度。 三个数值分别为 1分钟、5分钟、15分钟前到现在的平均值。如果这个数除以逻辑CPU的数量,结果高于5的时候就表明系统在超负荷运转了 |
第二行
| 内容 | 含义 |
|---|---|
| 94 total | 进程总数 |
| 1 running | 正在运行的进程数 |
| 93 sleeping | 睡眠的进程数 |
| 0 stopped | 停止的进程数 |
| 0 zombie | 僵尸进程数 |
第三行
%Cpu(s): 0.0 us, 3.2 sy, 0.0 ni, 96.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
| 内容 | 含义 |
|---|---|
| 0.0 us | 用户空间占用CPU百分比 |
| 3.2 sy | 内核空间占用CPU百分比 |
| 0.0 ni | 用户进程空间内改变过优先级的进程占用CPU百分比 |
| 96.8 id | 空闲CPU百分比 |
| 0.0 wa | 等待输入输出的CPU时间百分比 |
| 0.0 hi | 硬中断(Hardware IRQ)占用CPU的百分比 |
| 0.0 si | 软中断(Software Interrupts)占用CPU的百分比 |
| 0.0 st |
第四行
KiB Mem : 1776196 total, 72544 free, 1545768 used, 157884 buff/cache
| 内容 | 含义 |
|---|---|
| KiB Mem : 1776196 total | 物理内存总 |
| 72544 free | 空闲内存总量 |
| 1545768 used | 使用的物理内存总量 |
| 157884 buff/cache | 用作内核缓存的内存量 |
第五行
KiB Swap: 0 total, 0 free, 0 used. 79840 avail Mem
| 内容 | 含义 |
|---|---|
| KiB Swap: 0 total | 交换区总量 |
| 0 free | 空闲交换区总量 |
| 0 used | 使用的交换区总量 |
| 79840 avail Mem | 代表可用于进程下一次分配的物理内存数量 |
| 列名 | 含义 |
|---|---|
| PR | 优先级 |
| NI | nice值。负值表示高优先级,正值表示低优先级 |
| VIRT | 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES |
| RES | 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA |
| SHR | 共享内存大小,单位kb |
| S | 进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程 |
| %CPU | 上次更新到现在的CPU时间占用百分比 |
| %MEM | 进程使用的物理内存百分比 |
| TIME+ | 进程使用的CPU时间总计,单位1/100秒 |
| COMMAND | 命令名/命令行 |
sort
对文本内容排序,以行为单位,默认以第一列ASCII 码的次序排列
重点参数说明
-b忽略每行前面开始出的空格字符。-r以相反的顺序来排序。-k n按指定的列进行排序。-u去重sort a.txt sort testfile -k 2
注意,sort排序后需要重定向输出
uniq
排序后去重
iconv
对于给定文件把它的内容从一种编码转换成另一种编码。
-f
iconv -c -t utf-8 test.txt -o tmp.txttee
既可以重定向到文件,还可以建立副本传向后续的stdin
(即打印输出又写入文件)
-a 选项为追加内容,类似>>
comm
Linux comm 命令用于比较两个已排过序的文件。
- -1 不显示只在第 1 个文件里出现过的列。
- -2 不显示只在第 2 个文件里出现过的列。
- -3 不显示交集列。
comm a.txt b.txtcurl
支持http https ftp等众多请求
直接curl + 地址 ,可输出网页源码
保存网页源码:
curl -o linux.html https://jayce.icu
curl https://jayce.icu >> jayce.html下载网页文件(不如用wget)
curl -O https://jayce.icu/hello.sh使用代理服务器:
curl -x 127.0.0.1:10809 https://jayce.icuLinux三剑客
grep
主要参数
[options]主要参数:
-c:只输出匹配行的计数。(count)
grep -c ftp /etc/passwd
-i:不区分大小写
grep -i FTP /etc/passwd
-h:查询多文件时不显示文件名。
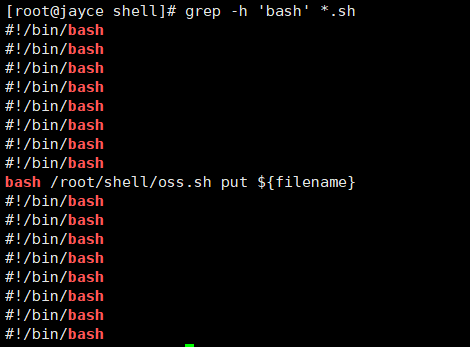
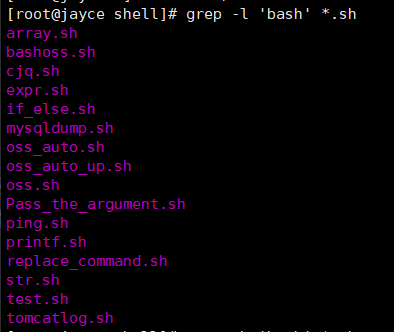
-l:查询多文件时只输出包含匹配字符的文件名。
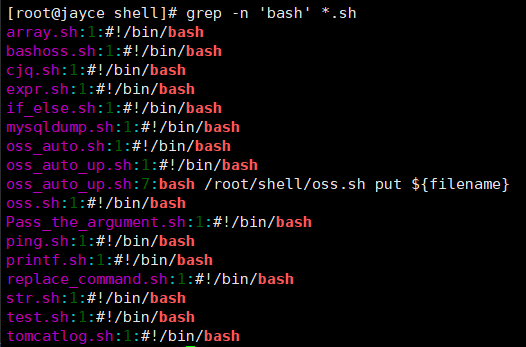
-n:显示匹配行及行号。
-s: 不显示不存在或无匹配文本的错误信息。
-v:显示不包含匹配文本的所有行。
输出相邻行
grep -A 1 bash oss.sh
grep -B 2 bash oss.sh
grep -C 3 bash oss.sh


总结:
-A选项,是 After 的缩写查看后面
-B选项,是 Before 的缩写查看前面
-C选项,它是-A和-B选项的合体两边都看
zgrep
zgrep 和 grep 用法类似,不过操作的对象是压缩的内容。支持 bzip2,gzip,lzip, xz 等等。
zgrep "/api" access_log.gz access_log_1.gzawk
awk '条件1{动作1} 条件2{动作2}..' filename df -h|grep "vda1"|awk '{printf $5 "\t\n"}'|cut -d "%" -f 1按照指定符号分割:
awk -F "." '{print $1}'
#复杂写法
awk 'BEGIN{FS="|";OFS="|"}{print $1,$2,$3,$4}' informix.txt条件
BEGIN
在所有数据读取之前执行这条命令
awk默认先读取第一行数据,如果
ps -ef|grep sshd|awk 'BEGIN{printf "输出进程号\n"} {print $2}'
如果没有BEGIN,则输出为
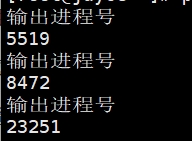
由此可见,BEGIN后的第一行是默认直接读取一次,不影响后面。
END
与BEGIN类似,读取最后一行
指定分隔符截取:
FS:输入分隔符
OFS:输出分隔符
多个分隔符:FS=“[,.]” 先以,分再以.分
awk 'BEGIN{FS="|";OFS="|"}{print $1,$2,$3,$4}' informix.txt
取出IP:
ifconfig eth0|grep -w 'inet'|awk 'BEGIN{FS="[. ]"}{print $10$11$12$13}'sed
sed利用脚本处理文本文件
语法:
sed [选项][脚本命令]文本文件选项
| 选项 | 含义 |
|---|---|
| -e 脚本命令 | 该选项会将其后跟的脚本命令添加到已有的命令中。 |
| -f 脚本命令文件 | 该选项会将其后文件中的脚本命令添加到已有的命令中。 |
| -n | 默认情况下,sed 会在所有的脚本指定执行完毕后,会自动输出处理后的内容,而该选项会屏蔽启动输出,需使用 print 命令来完成输出。 |
| -i | 此选项会直接修改源文件,要慎用。 |
脚本命令
address 表示指定要操作的具体行
pattern 指的是需要替换的内容
replacement 指的是要替换的新内容
flag标记如下:
| flags 标记 | 功能 |
|---|---|
| n | 1~512 之间的数字,表示指定要替换的字符串出现第几次时才进行替换,例如,一行中有 3 个 A,但用户只想替换第二个 A,这是就用到这个标记; |
| g | 对数据中所有匹配到的内容进行替换,如果没有 g,则只会在第一次匹配成功时做替换操作。例如,一行数据中有 3 个 A,则只会替换第一个 A; |
| p | 会打印与替换命令中指定的模式匹配的行。此标记通常与 -n 选项一起使用。 |
| w file | 将缓冲区中的内容写到指定的 file 文件中; |
| & | 用正则表达式匹配的内容进行替换; |
| \n | 匹配第 n 个子串,该子串之前在 pattern 中用 () 指定。 |
| \ | 转义(转义替换部分包含:&、\ 等)。 |
a :新增, 表示在指定行的后面附加一行
实例:
[address]a(或 i)\新文本内容 sed -e 4a\newLine mysql.txt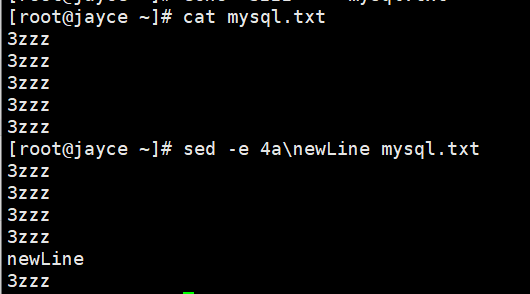
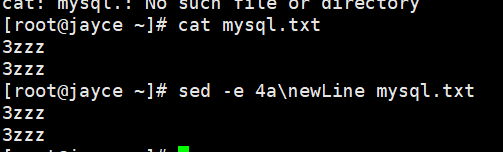
但是如果该文件不够4行,则:
c :替换整行
[address]c\用于替换的新文本 sed '3c\changed line' a.txt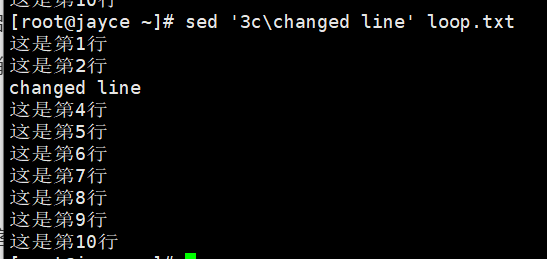
d :删除,因为是删除啊,所以 d 后面通常不接任何东东;
[address]d sed 'd' a.txt #什么也不输出,证明成了空文件 sed '3d' a.txt #删除第三行 sed '2,3d' a.txt sed '/1/,/3/d' a.txt sed '3,$d' a.txt #删除第三行之后所有的内容
在默认情况下 sed 并不会修改原始文件
i :新增, i 命令表示在指定行的前面插入一行,用法同a。
p :打印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行~
s :取代,replace
[address]s/pattern/replacement/flags sed '2s/first/second/2' a.txtsed 's/a/z/2' a.txt使用数字 2 作为标记的结果就是,sed 编辑器只替换每行中第 2 次出现的匹配模式。如果需要替换所有的字符串,需要用g标记
注意:在使用 s 脚本命令时,替换类似文件路径的字符串会比较麻烦,需要将路径中的正斜线进行转义,例如:
sed 's/\/bin\/bash/\/bin\/csh/' /etc/passwd去除转义字符后,红线为格式
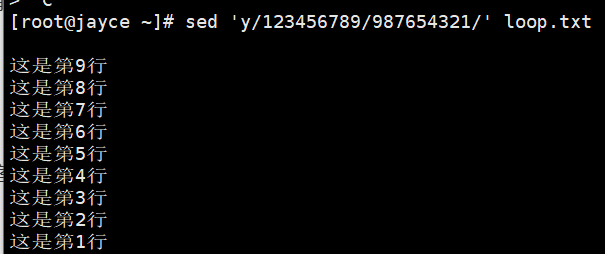
sed 's//bin/bash//bin/csh/' /etc/passwdy:y转换可以处理单个字符,对 inchars 和 outchars 值进行一对一的映射,为全局转换
[address]y/inchars/outchars/ sed 'y/123/789/' loop.txt命令将把1对应替换为7,2对应替换为8,3对应替换为9
VIM
命令模式
即进入vim时的模式,可以进行dd,i等操作
常用命令:
i切换至输入模式x删除当前字符:切换底线命令模式
| 移动光标 | |
|---|---|
| H | 屏幕的最上方一行的第一个字 |
| M | 屏幕的中央一行的第一个字 |
| L | 屏幕的最下方一行的第一个字 |
| G | 档案的最后一行(常用) |
| nG | n 为数字。移动到这个档案的第 n 行 |
| gg | 移动到这个档案的第一行,相当于 1G (常用) |
| n |
n 为数字。光标向下移动 n 行(常用) |
| 搜索替换 | |
|---|---|
| /word | 向光标之下寻找一个名称为 word 的字符串 |
| ?word | 向光标之上寻找一个名称为 word 的字符串 |
| n | 这个 n 是英文按键。代表重复前一个搜寻的动作。举例来说, 如果刚刚我们执行 /vbird 去向下搜寻 vbird 这个字符串,则按下 n 后,会向下继续搜寻下一个名称为 vbird 的字符串。如果是执行 ?vbird 的话,那么按下 n 则会向上继续搜寻名称为 vbird 的字符串! |
| N | 这个 N 是英文按键。与 n 刚好相反,为『反向』进行前一个搜寻动作。 例如 /vbird 后,按下 N 则表示『向上』搜寻 vbird 。 |
| 使用 /word 配合 n 及 N 是非常有帮助的!可以让你重复的找到一些你搜寻的关键词! | |
:n1,n2s/word1/word2/g |
n1 与 n2 为数字。 在第 n1 与 n2 行之间寻找 word1 这个字符串,并将该字符串取代为 word2 !举例来说,在 100 到 200 行之间搜寻 vbird 并取代为 VBIRD 则: :100,200s/vbird/VBIRD/g(常用) |
:1,$s/word1/word2/g或 :%s/word1/word2/g |
从第一行到最后一行寻找 word1 字符串,并将该字符串取代为 word2 !(常用) |
:1,$s/word1/word2/gc或 :%s/word1/word2/gc |
从第一行到最后一行寻找 word1 字符串,并将该字符串取代为 word2 ! 且在取代前显示提示字符给用户确认 (confirm) 是否需要取代!(常用) |
| 删除、复制与粘贴 | |
|---|---|
| nx | n 为数字,连续向后删除 n 个字符。举例来说,我要连续删除 10 个字符, 『10x』。 |
| dd | 剪切游标所在的那一整行(常用),用 p/P 可以粘贴。 |
| ndd | n 为数字。剪切光标所在的向下 n 行,例如 20dd 则是剪切 20 行(常用),用 p/P 可以粘贴。 |
| dnG | 删除光标所在到第n行的所有数据 |
| dG | 删除光标所在到最后一行的所有数据 |
| d$ | 删除游标所在处,到该行的最后一个字符 |
| d0 | 那个是数字的 0 ,删除游标所在处,到该行的最前面一个字符 |
| yy | 复制游标所在的那一行(常用) |
| nyy | n 为数字。复制光标所在的向下 n 行,例如 20yy 则是复制 20 行(常用) |
| ynG | 复制游标所在行到第一行的所有数据 |
| yG | 复制游标所在行到最后一行的所有数据 |
| y0 | 复制光标所在的那个字符到该行行首的所有数据 |
| y$ | 复制光标所在的那个字符到该行行尾的所有数据 |
| p, P | p 为将已复制的数据在光标下一行贴上,P 则为贴在游标上一行! 举例来说,我目前光标在第 20 行,且已经复制了 10 行数据。则按下 p 后, 那 10 行数据会贴在原本的 20 行之后,亦即由 21 行开始贴。但如果是按下 P 呢? 那么原本的第 20 行会被推到变成 30 行。 (常用) |
| u | 复原前一个动作。(常用) |
输入模式
底线命令模式
保存与退出
:w |
将编辑的数据写入硬盘档案中(常用) |
:w! |
若文件属性为『只读』时,强制写入该档案。 |
:q |
离开 vi (常用) |
:q! |
! 为强制离开不储存档案。 |
:wq |
储存后离开,wq! 则为强制储存后离开 |
:w [filename] |
将编辑的数据储存成另一个文件 (类似另存新档) |
:r [filename] |
读入另一个档案的数据。 将 [filename]内容加到游标所在行后面 |
:n1,n2 w [filename] |
将 n1 到 n2 的内容储存成 filename 这个档案。 |
:! command |
暂时离开 vi 到终端执行 command 的显示结果! |
查看与设置编码
查看
:set fileencoding设置
:set fileencoding=utf-8如果不用vim,可以用专门转码的命令 iconv,导航👉iconv
显示行号
| :set nu | 显示行号,设定之后,会在每一行的前缀显示该行的行号 |
| :set nonu | 与 set nu 相反,为取消行号! |
FTP
连接
ftp ip port
ftp 192.168.1.1 21文件的上传和下载都会在连接命令所在的目录下,即在/usr/local下执行ftp,则文件都下载到了/usr/local
下载
get
将文件从远端主机中传送至本地主机中
get /usr/local/1.txtmget
从远端主机接收一批文件至本地主机
cd /usr/your/
mget *.*在mget命令前先执行:prompt off,可去除每次提示



